¿Y ahora qué? ¿Qué hacemos? ¿Preocupado? En realidad no es para tanto, la misma “filosofía” de SQALE sigue ahí, con la deuda técnica y la calificación de deuda, pero ahora con un enfoque diferente.
Todos los cambios que han venido implementandose desde la versión 5.2 de SonarQube tenían como objetivo llegar a este punto. Las mejoras en los analizadores han permitido empezar a detectar con mayor precisión los defectos potenciales y las vulnerabilidades, así que es el momento de que tengan la importancia que se merecen.
¿Por qué un nuevo modelo?
Cuando se analiza la calidad del código con SonarQube uno de los problemas que más me encuentro en las organizaciones es “¿por dónde empezamos? ¿cuáles son las evidencias que hay que resolver primero?”.
Hasta ahora la respuesta siempre iba orientada a resolver las evidencias según su severidad: debes definir el perfil de calidad que quieres aplicar (conjunto de reglas y sus severidades), y después si una evidencia es bloqueante pues está claro que habrá que resolverla primero, ¿verdad?
Esto que parece tan sencillo provoca que se den situaciones un poco más complicadas:
¿Todas las evidencias bloqueantes detectan defectos reales?
La respuesta es no. Según quién crea el perfil de calidad puede darle más importancia a unas cosas que a otras. Por ejemplo, la falta de cobertura en una clase puede ser tratada como una evidencia bloqueante, pero eso no quiere decir que el código de esa clase tenga defectos. Lo mismo para el código duplicado o la complejidad.
¿Y al contrario? ¿Puede haber evidencias de poca severidad que detecten “bugs” o “vulnerabilidades” en producción?
Si, podría haberlas. Conozco muchos casos en los que la regla de inyección de código en las consultas de base de datos no es ni bloqueante ni crítica, por ejemplo. Incluso las reglas que detectan problemas de Null Pointer a veces se configuran sin las severidades máximas.
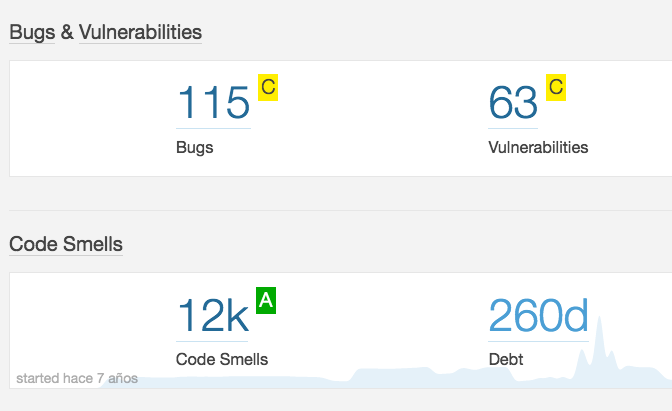
¿Tener una calificación A de deuda garantiza un código libre de bugs?
La respuesta es no. Y este es quizás el argumento más razonable a la hora de cambiar el modelo. Podíamos encontrarnos proyectos con una deuda muy baja, con la que obtienen una calificación de A, pero con un bug que provocase un ClassCastException en el código más crítico. Esto no tenía ningún sentido y tiene que reflejarse de algún modo.
Así que en mi opinión esto es precisamente lo que estaba ocurriendo y lo que debe aclarar el nuevo modelo:
Era muy difícil diferenciar cuando una evidencia estaba causando un problema de verdad de cuando se trataba simplemente de una normativa por política de desarrollo, o de una buena práctica.
Por eso el nuevo enfoque y separar en tres elementos diferentes las evidencias: bugs, vulnerabilidades y todo lo demás (code smells, hediondez del código o código que huele mal).
Los tres ejes del nuevo modelo
Efectivamente, dado que las evidencias se clasifican ahora en tres grupos, pues el nuevo modelo incluye tres características a las que deben asociarse:
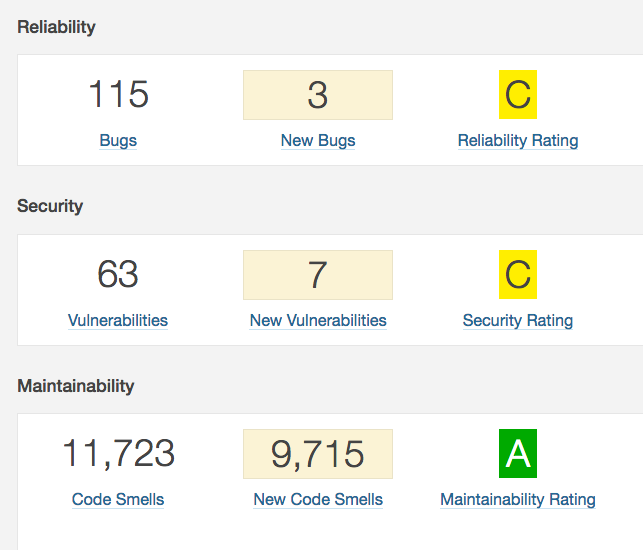
Fiabilidad
Incluye las evidencias de tipo bug. Un bug representa algo que está mal en el código. Si el software aún no se ha roto, se romperá, y probablemente en el peor momento. Todos los bugs tienen que solucionarse sí o sí. ¿Cuando? Ayer.
Seguridad
Incluye las evidencias de tipo vulnerabilidad, que representan una potencial puerta trasera para atacantes. El caso de las evidencias de seguridad es un poco más especial que el resto, porque la casuística es mucho mayor y los matices también. Por ejemplo, no podemos saber si una evidencia está afectando a datos sensibles o no. Por eso aquí se van a encontrar todas las evidencias que tengan una mínima sospecha de afectar a la seguridad. Es responsabilidad de una persona eliminar los falsos positivos y centrarse en resolver los casos reales.
Mantenibilidad
Incluye las evidencias de tipo code smells, que al final son todas esas malas prácticas que a la larga van a provocar que cada vez sea más difícil hacer cambios en el código. En el peor de los casos, todos estos malos olores van a hacer que los desarrolladores se confundan, lo que terminará introduciendo nuevos bugs.
¿Y las nuevas calificaciones?
Pues resulta que para cada una de las características se calcula la calificación de una forma diferente. Si, como lo lees. A mí esto es lo que menos me ha gustado, y pienso que será un problema de cara a transmitirlo a los equipos. Pero es verdad que una vez te mentalizas y sabes que son diferentes pues ya no es tanto problema:
- Para la mantenibilidad se mantiene el mismo cálculo que existía en versiones anteriores usando el modelo SQALE y el ratio de deuda técnica. La calificación SQALE ahora es la calificación de mantenibilidad.
- Para la fiabilidad y la seguridad se ha introducido una nueva fórmula: la calificación dependerá de la severidad más alta de los bugs o vulnerabilidades detectadas.
- si existe al menos una bloqueante, la calificación será E
- si existe al menos una crítica, la calificación será D
- si existe al menos una mayor, la calificación será C
- si existe al menos una menor, la calificación será B
- si no existe ningún bug o vulnerabilidad, la calificación es A
Se sigue manteniendo el esfuerzo de resolución de la evidencia en todos los casos, sean bugs, vulnerabilidades o code smells, lo que permite conocer una estimación (que puede ser más o menos precisa) de lo que costaría resolver los problemas.
Tiene todo el sentido del mundo y como decía al principio, los bugs y vulnerabilidades ahora tienen más importancia. Ahora tu proyecto puede estar muy bien y tener una calificación de A en mantenibilidad, pero si se han detectado bugs en el código, esto se verá reflejado.
En resumen…
- Las evidencias (issues) se categorizan ahora en tres tipos: bugs, vulnerabilidades y code smells.
- Desaparecen las características de calidad del modelo SQALE, que se sustituyen por fiabilidad, seguridad y mantenibilidad, que se corresponden con el tipo de evidencia que incluyen.
- La calificación de mantenibilidad es ahora lo que antes era la calificación de deuda, calculado en base al ratio de deuda.
- La calificación de fiabilidad y seguridad se calculan teniendo en cuenta la severidad más alta de las evidencias detectadas
¿Qué te parece? ¿Conocías el nuevo modelo o te has llevado una sorpresa? ¿Crees que este nuevo enfoque ayudará a mejorar aún más tu código?